
【AIGC系列】AI歌曲翻唱
相关调研
在线工具
- (要钱)Covers.AI:Covers.AI 提供了一个简单的流程,选择歌曲和AI声音模型后即可生成翻唱,适合没有技术背景的用户。
- (麻烦,开规则不让用,开全局又卡)TopMediai AI:TopMediai AI Song Cover 允许用户从7000多个AI模型中选择,上传歌曲或YouTube链接后生成高质量翻唱,支持合唱和二重唱。
- (普通用户每天3次,而且不稳定)Musicfy AI:Musicfy AI 提供使用版权免费声音和自定义AI模型的功能,适合音乐家和内容创作者探索独特的声音风格。
- (巨难下载)Replay:Replay
开源项目
操作技术栈
找原始训练素材音频
下载视频(bilidown)
拿主播XDD为例,一般只能拿到直播时候的视频,这里我推荐从b站下载别人的录播,比较方便。这里我推荐使用bilidown下载,可以单独保存音频。
截取音频的人声(剪映/AU)
因为我们只需要获得想要训练的人物的人声即可,所以我选择使用剪映,将需要的人声都剪出来。
一般来说4/5min人声即可,但是如果想要得到更好的效果,可以选择10min以上。
uvr5处理歌曲/训练集
uvr5简介以及简单操作指南
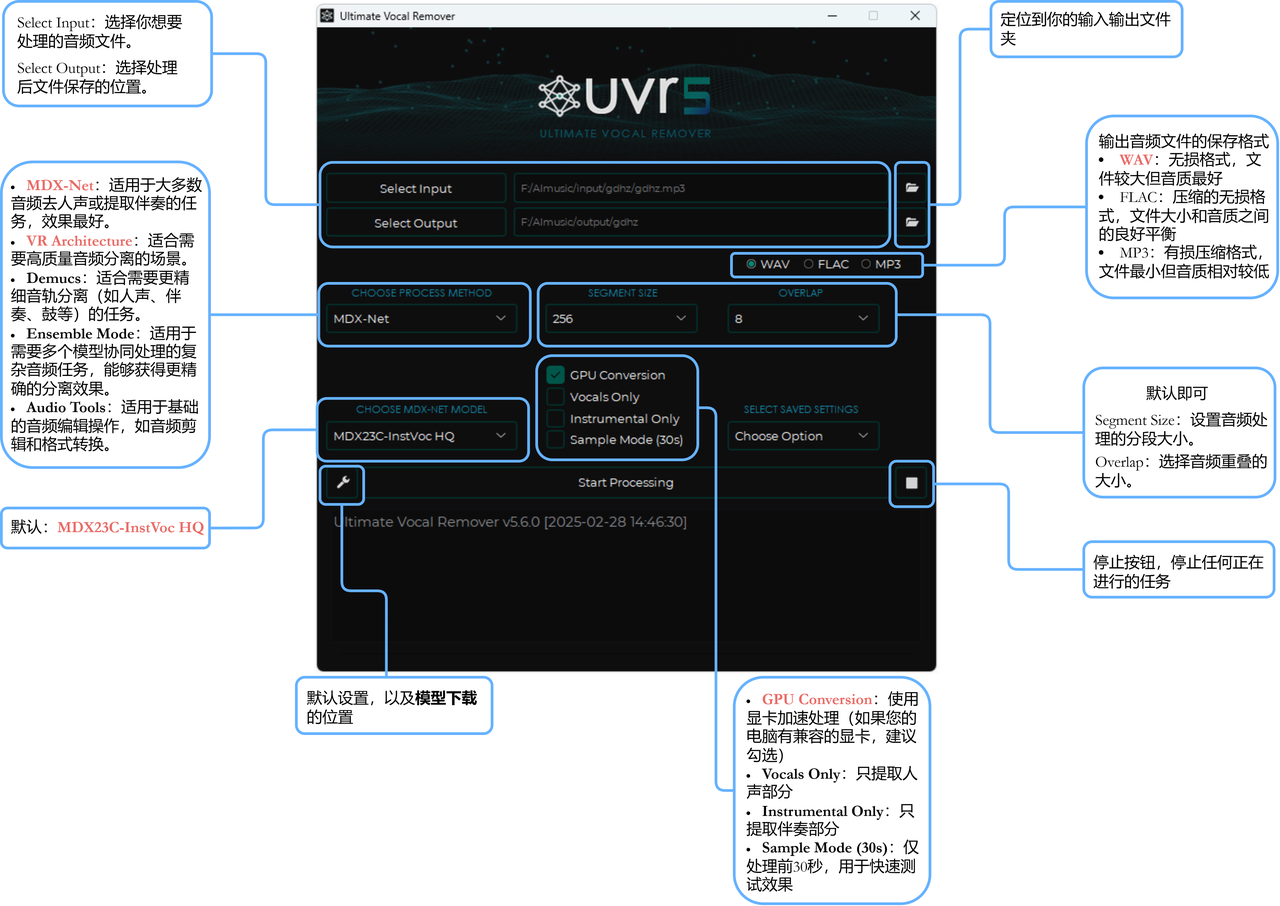
uvr5进阶指南
⭐什么模型适合我(重点)⭐
(知乎大佬总结的)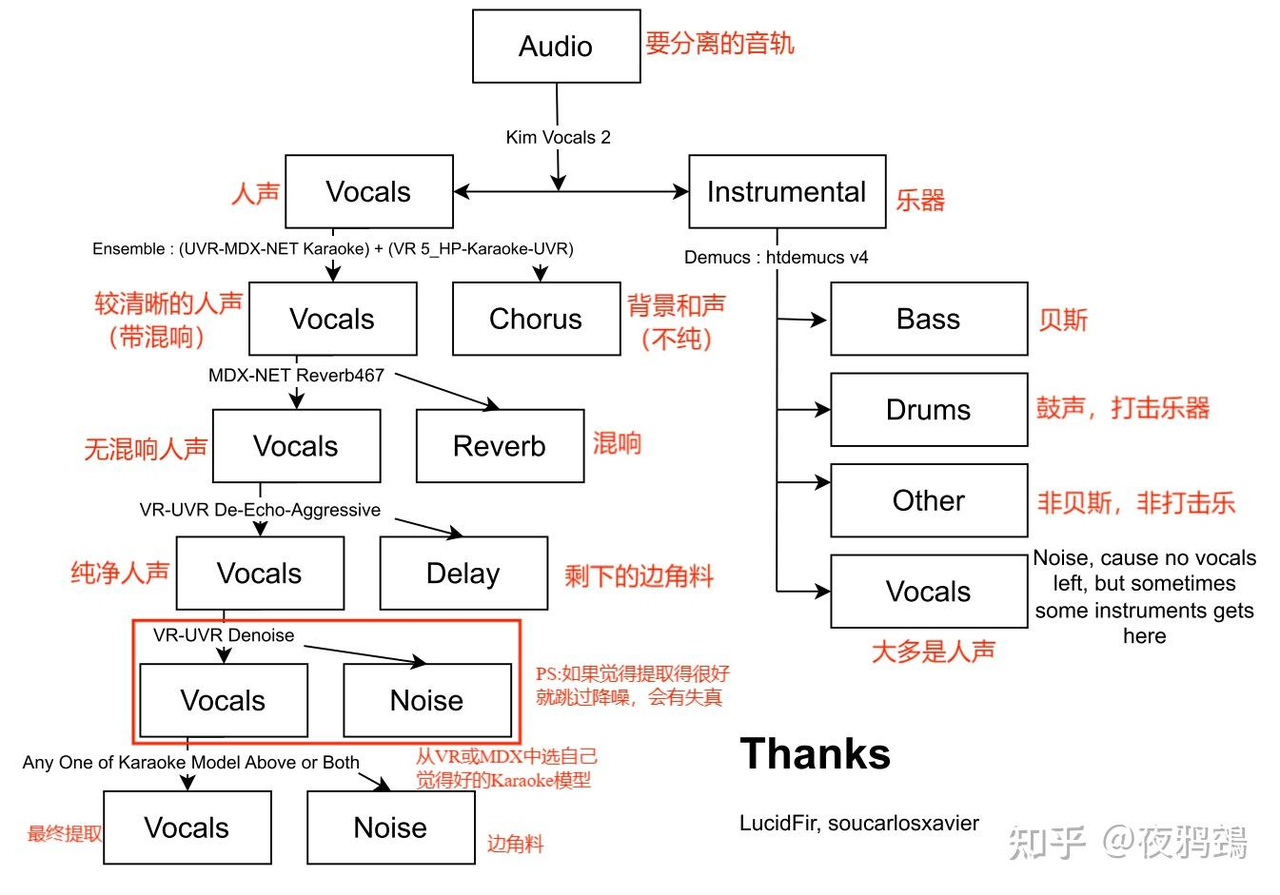
- 不管什么类型的音轨分离人声,我的建议首选Kim Vocal 1或者2,分离得不好再按照图中所示。
- 并不是分离得越多越好,当你认为现在的音轨符合你要求,就可以结束了。分离得越多,失真机率跟着上升
- VR UVR-DeNoise不仅有降噪,还可以识别较重的呼吸声(一些特殊音效识别可以自己上手测试)。
- 提取音乐中的副歌人声:点击【扳手图标】→Additional Settings→Vocal Splitter Options→按图中所示选择→再次分离音轨后,此时带vocal名称的便是副歌
进阶版(乐器类): - VR:序号17 Wind_inst是指提取音轨中的木管部分(不是风声!),现阶段AI还未完全学透,所以过于复杂的音轨分离需要降低期待值
- MDX:里面有3个MDX23C模型,是团队最近培训的AI模型,融合了Github很多人的意见,属于AI中计算力最厉害的一批,但电脑如果没有GPU的话分离的时间会很漫长。如果会科学上网的话,建议来Google Colab,速度快很多。参数设置:bigShifts:11;overlap_instvoc:8;overlap_vitlarge:8;要点voc_ft checked,虽然会花时间,但分离出来的音轨会更好;weight_vocft to 1;其他设置默认
- Demucs:最新版5.6出了v4 | htdemucs_6s,多了吉他和钢琴音轨,还不错
- Demucs:如果是复制了我的model文件夹,会多出一个drumsep,这是外网的一位老哥自己训练的AI模型,他在讨论区分享出来,主要用于架子鼓声的分离。因为主创团队还未为其写stems,所以显示仍然只有vocal,other,bass,drum。vocal:嗵鼓; other:吊镲&踩镲; bass:小鼓;drum:低音大鼓/底鼓
- Ensemble Mode(合奏模式)通过选择ensemble algorithm中的Spec,来调节CPU/GPU处理速度和产出质量,Max质量好速度慢,Min速度快质量良。比如只提取乐器就Vocals/Instrumental 选Min/Max,如果不知道怎么选就两个average
UVR5 不同处理方法的模型推荐
MDX-Net 模型推荐
- (通常只选择一次这个模型)MDX23C-InstVoc HQ: 提供极高质量的人声/伴奏分离,适合大多数商业音乐。
- UVR-MDX-NET-Inst_Main: 专为提取纯伴奏优化,对于流行音乐效果尤佳。
- UVR-MDX-NET-Voc_Main: 专为提取人声优化,能有效保留人声细节。
- MDX-B: 平衡型模型,处理速度较快且音质不错,适合初次尝试。
- Kim_Vocal_1: 针对亚洲流行音乐优化,对于中/日/韩语歌曲效果出色。
VR Architecture 模型推荐
- 6_HP-Karaoke-UVR: 有效去除人声中的和声。
- VR-DeEchoDeReverb: 能有效去除人声中的回声和混响,适合处理现场录音。
- 3Band-HighEnd: 对高频分离效果出色,适合处理含有高音乐器的音乐。
- 5-UVR: 全频段分离效果均衡,是VR架构下的通用选择。
Demucs 模型推荐
- Demucs_HT: 四轨分离效果出色,可同时分离人声、鼓、贝斯和其他乐器。
- Demucs_6S: 六轨分离模型,增加了吉他和钢琴轨道,适合更复杂的音乐分解。
- Demucs_2S: 双轨(人声/伴奏)分离的轻量级模型,处理速度快,适合简单分离任务。
- UVR_Demucs_Model_1: 针对UVR优化的Demucs模型,平衡了速度和质量。
Ensemble Mode 模型组合推荐
- MDX-Net + VR: 结合MDX-Net的音色保真度和VR的细节处理能力,适合要求极高的专业分离。
- Demucs + MDX-Net: 利用Demucs的多轨分离和MDX-Net的人声分离优势,适合制作多轨混音项目。
- 多个MDX-Net变体: 使用不同参数训练的MDX-Net模型组合,能在不同频段达到最佳效果。
Audio Tools 模型/工具推荐
- Noise Reduction: 有效降低背景噪音,适合清理录音或旧音频文件。
- Pitch Shifter: 提供高质量的音高调整,适合创作变调效果。
- Time Stretcher: 在保持音高的情况下改变速度,适合节奏调整。
- Normalization Tool: 标准化音频电平,使多个音频片段保持一致的响度。
每种处理方法都有其特定的应用场景,建议根据您的具体需求选择合适的模型,并通过小样本测试找到最适合您音频材料的选项。
参考教程
音频切分(slicer)
slicer简单使用指南
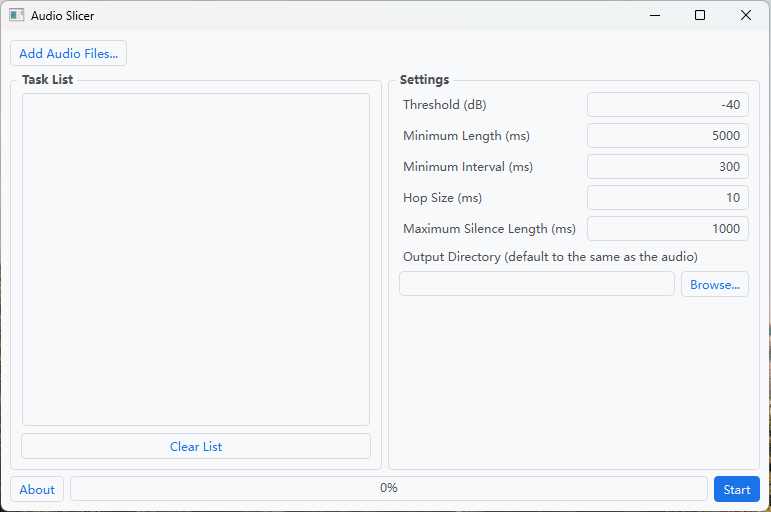
参数说明(来源官网),图中的参数值均为默认值
- Threshold(阈值):以 dB(分贝)表示的 RMS 阈值。所有 RMS 值都低于此阈值的区域将被视为静音。如果音频有噪音,增加此值。
- Minimum Length(最小长度):以默认值 5000(毫秒为单位)为例,简单来说就是切割后的每个音频片段都不少于 5 秒。
- Minimum Interval(最小间距):以默认值 300(毫秒为单位)为例,简单来说就是少于 0.3 秒的静音不会被切割丢掉,超过 0.3 秒的静音部分才丢掉。如果音频仅包含短暂的中断,请将此值设置得更小。此值越小,此应用程序可能生成的切片音频剪辑就越多。请注意,此值必须小于 minimum length 且大于 hop size。
- Hop Size(跳跃步长):每个 RMS 帧的长度(说白了就是精度),以毫秒为单位。增加此值将提高切片的精度,但会降低处理速度。默认值为 10。
- Maximum Silence Length(最大静音长度):在切片音频周围保持的最大静音长度,以毫秒为单位。根据需要调整此值。请注意,设置此值并不意味着切片音频中的静音部分具有完全给定的长度。如上所述,该算法将搜索要切片的最佳位置。默认值为 1000。
参考教程
训练模型(RVC)
- 找4-5min的训练素材
- uvr5处理的到pure人声
- 音频切分(slicer)
参考教程
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 sbemo!